Chinese restaurant process
In probability theory, the Chinese restaurant process is a discrete-time stochastic process, whose value at any positive-integer time n is a partition Bn of the set {1, 2, 3, ..., n} whose probability distribution is determined as follows. At time n = 1, the trivial partition { {1} } is obtained with probability 1. At time n + 1 the element n + 1 is either:
- added to one of the blocks of the partition Bn, where each block is chosen with probability |b|/(n + 1) where |b| is the size of the block, or
- added to the partition Bn as a new singleton block, with probability 1/(n + 1).
The random partition so generated is exchangeable in the sense that relabeling {1, ..., n} does not change the distribution of the partition, and it is consistent in the sense that the law of the partition of n − 1 obtained by removing the element n from the random partition at time n is the same as the law of the random partition at time n − 1.
Contents |
Definition
One fancifully imagines a Chinese restaurant with an infinite number of circular tables, each with infinite capacity. Customer 1 is seated at an unoccupied table with probability 1. At time n + 1, a new customer chooses uniformly at random to sit at one of the following n + 1 places: directly to the left of one of the n customers already sitting at an occupied table, or at a new, unoccupied circular table. Clearly, each table corresponds to a block of a random partition. (For an account of the custom in actual Chinese restaurants, see table sharing). It is then immediate that the probability assigned to any particular partition (ignoring the order in which customers sit around any particular table) is
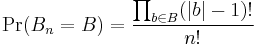
where b is a block in the partition B and |b| is the size (i.e. number of elements) of b. The restaurant analogy is due to Pitman and Dubins, and first appears in print in [1].
Generalization
This construction can be generalized to a model with two parameters, α and θ,[2][3] commonly called the discount and strength (or concentration) parameters. At time n + 1, the next customer to arrive finds |B| occupied tables and decides to sit at an empty table with probability
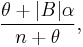
or at an occupied table b of size |b| with probability
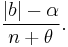
In order for the construction to define a valid probability measure it is necessary to suppose that either α < 0 and θ = - Lα for some L ∈ {1, 2, ...}; or that 0 ≤ α ≤ 1 and θ > −α.
Under this model the probability assigned to any particular partition B of n is
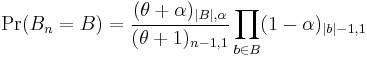
where, by convention, 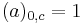 , and for
, and for 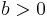
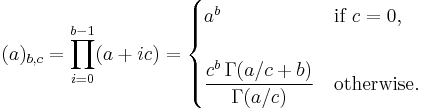
Thus the partition probability can be expressed in terms of the Gamma function as
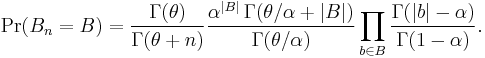
In the one-parameter case, where  is zero, this simplifies to
is zero, this simplifies to
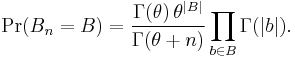
As before, the probability assigned to any particular partition depends only on the block sizes, so as before the random partition is exchangeable in the sense described above. The consistency property still holds, as before, by construction.
If α = 0, the probability distribution of the random partition of the integer n thus generated is the Ewens distribution with parameter θ, used in population genetics and the unified neutral theory of biodiversity.
Derivation
Here is one way to derive this partition probability. Let Ci be the random block into which the number i is added, for i = 1, 2, 3, ... . Then
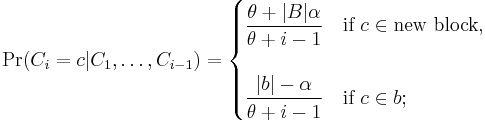
The probability that Bn is any particular partition of the set { 1, ..., n } is the product of these probabilities as i runs from 1 to n. Now consider the size of block b: it increases by 1 each time we add one element into it. When the last element in block b is to be added in, the block size is (|b| − 1). For example, consider this sequence of choices: (generate a new block b)(join b)(join b)(join b). In the end, block b has 4 elements and the product of the numerators in the above equation gets θ · 1 · 2 · 3. Following this logic, we obtain Pr(Bn = B) as above.
Expected number of tables
For the one parameter case, with α = 0 and 0 < θ < ∞, the expected number of tables, given that there are  seated customers, is[4]
seated customers, is[4]
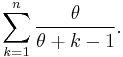
In general case (α > 0) the expected number of occupied tables is[3]
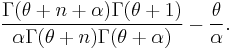
The Indian buffet process
It is possible to adapt the model such that each data point is no longer uniquely associated with a class (i.e. we are no longer constructing a partition), but may be associated with any combination of the classes. This strains the restaurant-tables analogy but can instead be described as a process in which each diner samples from some subset of an infinite selection of dishes on offer at a buffet. The probability that a particular diner samples a particular dish is proportional to the popularity of the dish among diners so far, and in addition the diner may sample from the untested dishes. This has been named the Indian buffet process and can be used to infer latent features in data.[5]
Applications
The Chinese restaurant process is closely connected to Dirichlet processes and Polya's urn scheme, and therefore useful in applications of nonparametric Bayesian methods including Bayesian statistics. The Generalized Chinese Restaurant Process is closely related to Pitman–Yor process. These processes have been used in many applications, including modeling text, clustering biological microarray data, biodiversity modelling and detecting objects in images .
References
- ^ D. Aldous, "Exchangeability and Related Topics", in l'École d'été de probabilités de Saint-Flour, XIII–1983, pages 1–198. Berlin: Springer
- ^ Pitman, Jim (1995). "Exchangeable and Partially Exchangeable Random Partitions". Probability Theory and Related Fields 102 (2): 145–158. doi:10.1007/BF01213386. MR1337249.
- ^ a b Pitman, Jim (2006). Combinatorial Stochastic Processes. Berlin: Springer-Verlag. http://works.bepress.com/jim_pitman/1/.
- ^ Xinhua Zhang, "A Very Gentle Note on the Construction of Dirichlet Process", September 2008, The Australian National University, Canberra. Online: http://www.stat.purdue.edu/~zhang305/pubDoc/notes/dirichlet_process.pdf
- ^ Griffiths, T.L. and Ghahramani, Z. (2005) Infinite Latent Feature Models and the Indian Buffet Process. Gatsby Unit Technical Report GCNU-TR-2005-001.
External links
- A talk by Michael I. Jordan on the CRP: